There is a straightforward reason why two companies can start AI development at the same time, use comparable model architectures, and arrive at dramatically different results: the quality of their training data. Before a single parameter is tuned or a single inference is made, the labeled dataset sitting underneath the model determines its ceiling. Professional data annotation services are what close the gap between raw data and production-ready training sets — and in 2026, with AI systems operating in higher-stakes environments than ever before, the difference between annotation done well and annotation done cheaply is measured in model failures that are expensive, sometimes damaging, and entirely preventable.
What Professional Data Annotation Services Cover
The scope of what a full-service annotation provider handles goes well beyond drawing boxes around objects or tagging text with labels. A professional engagement covers the entire data preparation pipeline: defining the annotation schema in collaboration with the client’s AI team, recruiting and training annotators with the domain knowledge the project requires, running pilot batches to validate guidelines before full-scale production begins, maintaining quality assurance throughout the project lifecycle, and delivering structured datasets in the formats and splits that training pipelines require.
This end-to-end ownership matters because the decisions made at the earliest stages — how edge cases are defined, how ambiguous examples are handled, what constitutes a valid label versus an uncertain one — propagate through every subsequent phase. An annotation partner that takes ownership of the full process produces more consistent datasets than one that simply executes labeling instructions without engaging with the underlying task design.
Image and Video Annotation for Computer Vision
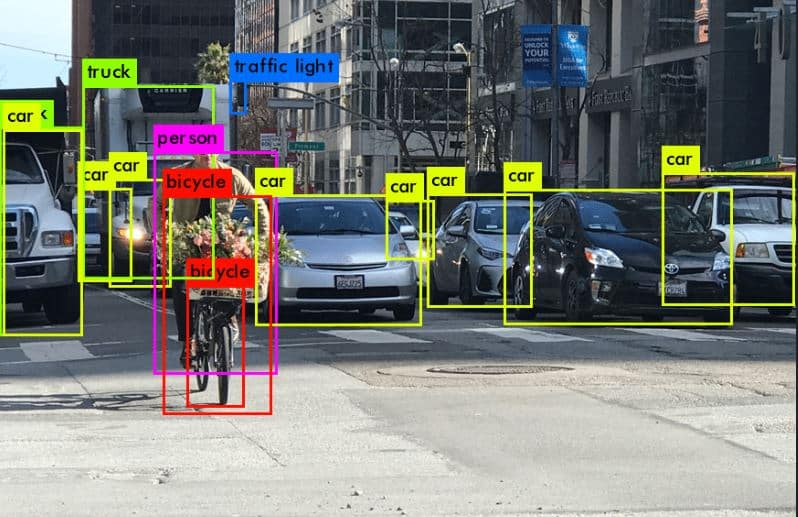
Computer vision remains one of the highest-demand areas for data annotation services, and the range of techniques involved reflects the diversity of applications being built. Bounding box annotation is the foundation of object detection, placing rectangular frames around instances of target classes across image and video datasets. Polygon and segmentation annotation goes further, tracing the precise outline of objects at the pixel level for applications where detection alone is insufficient — surgical robotics, quality control inspection, and scene understanding in autonomous systems.
Keypoint annotation marks specific structural points on objects and bodies, providing the training data for pose estimation models used in sports analytics, physical therapy applications, and motion capture for animation. Video annotation extends all of these techniques across time, requiring annotators to track objects consistently across frames and label temporal events with accurate start and end boundaries. Each technique demands different skills, different tooling, and different quality control approaches — which is why generic annotation workforces consistently underperform specialized ones on computer vision projects.
Text and NLP Annotation for Language Models
The demand for high-quality text annotation has grown in direct proportion to the expansion of large language model development. Named entity recognition annotation identifies and classifies mentions of specific concept types within documents — people, organizations, products, medical terms, legal references — providing the labeled examples that NLP models use to learn extraction tasks. Sentiment and intent annotation assigns categorical labels to text at varying levels of granularity, from document-level classification to phrase-level tagging, supporting the development of models used in customer experience, market intelligence, and content moderation.
Instruction and preference annotation has become a critical category in 2026, driven by the widespread adoption of RLHF as a model alignment technique. Human annotators write and evaluate model responses according to defined quality criteria — accuracy, helpfulness, tone, safety — and their judgments train the reward models that guide LLM fine-tuning. This type of annotation requires annotators who can apply nuanced judgment consistently, not just follow a binary labeling schema, and the quality of the resulting models reflects the quality of the human feedback directly.
Audio and Speech Annotation for Voice AI
Voice-based AI applications have expanded significantly across customer service, healthcare, accessibility tools, and consumer devices, and each of them depends on accurately annotated audio training data. Speech transcription annotation converts recordings into text with precise speaker attribution, punctuation, and where relevant, timing alignment between transcript and audio. This is not simple transcription — annotation teams working on AI training data apply additional layers that pure transcription services do not, including acoustic event labeling, dialect and accent classification, and quality flagging for audio segments that fall below usability thresholds.
Emotion and sentiment annotation on audio adds a dimension that text-based annotation cannot capture: the paralinguistic signals in voice — pitch, pace, energy, hesitation — that carry meaning independent of the words being spoken. Models trained on this data underpin the sentiment analysis tools used in contact center quality management, mental health monitoring applications, and conversational AI systems designed to detect and respond to user emotional state.
Quality Assurance as a Core Component, Not an Add-On
The most important differentiator between data annotation services that deliver production-ready datasets and those that deliver volume without reliability is the structure of the quality assurance process. In low-quality annotation operations, QA is a final check — a sample review at the end of a batch that catches obvious errors but misses systematic inconsistencies that have compounded across thousands of examples. In professional operations, QA is embedded throughout the workflow.
Inter-annotator agreement measurement quantifies how consistently multiple annotators label the same inputs, surfacing calibration problems before they contaminate large portions of the dataset. Annotation audits at regular intervals catch annotators who have drifted from guidelines as a project progresses. Automated consistency checks flag statistical outliers — labels that appear at frequencies inconsistent with the dataset’s expected distribution — for human review. And structured feedback loops return identified errors to annotators with specific guidance, correcting behavior rather than simply rejecting output.
Scaling Data Annotation Services Without Sacrificing Quality
Growing annotation throughput is straightforward. Maintaining quality as throughput grows is the challenge that separates annotation providers with real operational maturity from those that scale by diluting standards. The operations that manage this well build quality control overhead into the process from the start rather than treating it as a variable to be reduced when timelines tighten.
Model-assisted pre-labeling accelerates throughput on datasets where a preliminary model can generate plausible initial labels that annotators review and correct rather than creating labels from scratch. When implemented carefully — with human review calibrated to the pre-labeling model’s known failure modes — this approach maintains annotation quality while meaningfully reducing time and cost on high-volume projects. When implemented carelessly, it replicates existing model biases into the new training set, which defeats the purpose of the annotation exercise.
Choosing Data Annotation Services That Match Your Project Requirements
The evaluation criteria that matter most when selecting an annotation partner are specific to the data types and domain involved. Annotator expertise in the relevant field — medical, legal, technical, multilingual — is not interchangeable with general labeling experience, and the performance gap between domain-matched and generalist annotation teams is most visible on the edge cases that determine model robustness.
Transparency in quality reporting is a reliable indicator of operational maturity. Partners that provide inter-annotator agreement scores, error rate breakdowns by annotation category, and annotator-level performance data are operating with the kind of visibility that produces consistent datasets. Those that report only completion rates and delivery timelines are managing throughput, not quality.
The right data annotation services partner treats labeled data as the asset it actually is — the foundation that every stage of AI development builds on — and structures their process accordingly.